Qué decimos cuando no decimos nada: Claves del cambio lingüístico inducido por contacto en las pausas llenas del español conversacional
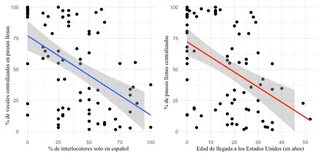 Tasa de vocal de pausa llena centralizada por porcentaje de interlocutores solo en español y edad de llegada.
Tasa de vocal de pausa llena centralizada por porcentaje de interlocutores solo en español y edad de llegada.Resumen
Este estudio examina la variación en la calidad de las vocales de pausas llenas producidas por 80 hispanohablantes residentes de Boston, MA en el contexto de entrevistas sociolingüísticas. El análisis estadístico revela patrones consistentes con el cambio lingüístico inducido por contacto: las personas que llegaron a los EE. UU. como adultos y que hablan exclusivamente español con la mayoría de sus interlocutores (es decir, familiares, amigos y compañeros de trabajo) prefieren llenar las pausas en el habla espontánea en español con eh/em. Por el contrario, aquellos que nacieron o llegaron a los EE. UU. de niños y/o que hablan exclusivamente español con menos interlocutores son significativamente más propensos a usar ah/am y uh/um. Interpretamos esta diferencia como prueba de un reordenamiento de las normas de llenado de pausas entre aquellos que tienen mayor experiencia con el inglés. Nuestros resultados se alinean con una visión del contacto lingüístico como potencial productor de una innovación lingüística que está limitada por la estructura de los sistemas lingüísticos.
Esta es una traducción, ofrecida por el Observatorio, del original inglés remitido por los autores.
Tipo
Publicación
Estudios del Observatorio, 80, pp. 1-31
Nota
Esta es una traducción, ofrecida por el Observatorio, del original inglés remitido por los autores. This is a translation, provided by the Observatorio, of the English original submitted by the authors.

Autores
Daniel G. Erker
(he/him)
Profesor Asociado
Sociolingüista variacionista y Profesor Asociado en el Departamento de Lingüística de Boston University.

Autores
Lee-Ann Vidal Covas
(she/her)
Investigadora (PhD, Boston University) con experiencia en investigación sociolingüística, curación de conjuntos de datos y ciencia de datos aplicada.